
明天要考试了,现在来梳理一下这学期学的R语言吧
数据类型
- 整数
- 小数
- 字符串 双引号和单引号一样
- 布尔类
T,TRUEF,FALSE
数据类型转换
判断类型
#判断是否是数字 (整数+浮点数)
is.numeric(x)
is.character(x)
is.logical(x)
class(x)
类型转换
as.numeric(x)
as.character(x)
as.logical(x)
运算符号
| 符号 | 用法 |
|---|---|
| 加法 | a + b |
| 减法 | a - b |
| 乘法 | a * b |
| 除法 | a / b |
| 整除 | a %/% b |
| 取模 | a %% b |
| 次方 | a ^ 2 |
| 不等 | a != b |
| 且 | a & b |
| 或 | a | b |
| 非 | ! b |
| 四舍五入 | round() |
| 取上整 | ceiling() |
| 取下整 | floor() |
数据集
向量
应该是R语言最常用的数据结构了
同一个向量里,所有的数据类型都要一致
赋值
vec<-c(1,2,3,4)
取值
vec[3]
# 3
取长度
length(vec)
取出多个
用另一个向量取出来
vec[c(1,3,4)]
# 1 3 4
快速获得一个连续的向量
vec<-1:20
# 等价于
vec<-c(1,2,3,4 ... 19,20)
vec<-seq(1,50,2)
# 等价于
vec<-c(1,3,5,7 ... 47,49)
向量运算
向量运算是一一对应的运算,两个向量的长度要一样,或者是整数倍的关系(这样短的就能复制自己)
a<-c(1,2,3)
b<-c(4,5,6)
a + b
# c(1+4,2+5,3+6)
a * b
# c(1*4,2*5,3*6)
a + 2
# c(1*2,2*2,3*2)
rank(vec)
# 排名函数,升序,最小的是第1名
因子 factor
用于存储非定量的多分类数据(性别…)
目的是给这些没有大小、数值关系的数据排序
x<-c('中','优','良')
sort(x)
# 良 优 中 (用拼音来排序)
x1<-factor(x,levels=c('优','中','良'))
sort(x1)
# 优 中 良
列表 list
把多个向量放在一起,多个向量间可以数据类型不同,甚至不止能放向量,想放啥放啥
listSample<-list(Student=c('Tom','Kobe'),Year=2017,Score=c(60,50),school="CGU")
取数据
两种方法,一种是参数中的名字,另一种是用下标访问,下标要用两层括号
listSample$Student
listSampel[[1]]
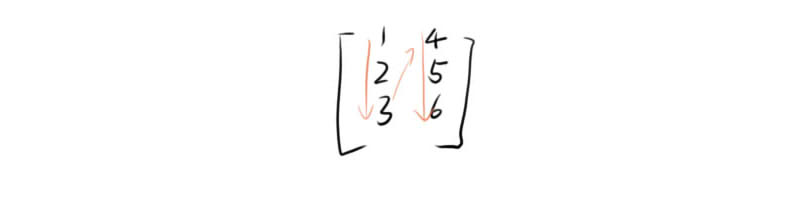
矩阵 matrix
感觉不会考,稍微记一下
mx<-matrix(c(1:6),nrow=3,ncol=2)
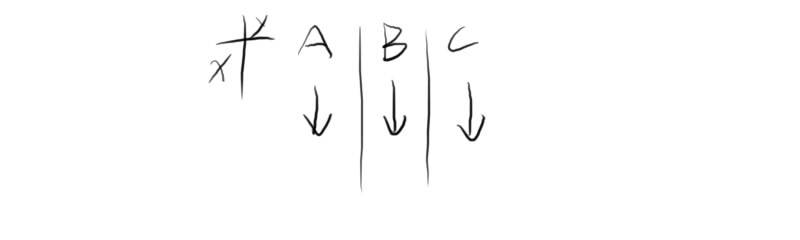
数据框 data.frame
感觉是重点考察对象
数据框是特殊的列表,要求所有向量的长度必须相等
x<-data.frame(A=c(1,2,3),B=c(1,2,3))
colnames(x)
# 列名 A B
rownames(x)
# 行名 1 2 3
取出
数据框更像是一张数据库的数据表,创建时的参数都是一个个字段,而不是一条条记录
data.frame[x,y]
# 第x行第y个字段
data.frame[y]
# 第y个字段,其实等价data.frame[,y]
data.frame[,y]
# 第y列
data.frame[x,]
# 第x行
字符串
正则表达式没什么好说的,知道^是开头,$是结尾就好了
nchar("hello") #取字符串长度
strsplit(xx,".") #类似python的"".split()
substr(xx,start,end) #指定起点和终点,不是长度
toupper(x)
tolower(x)
paste(xx,yy,sep=".") #拼接字符串
grep(regex,c(xx)) #返回向量中匹配的下标
grepl(regex,c(xx)) #返回一个参数向量等长的向量,表示是否匹配
语法
感觉解释型语言的语法都差不多,就是这个else必须在if的}同行让我有点反感
判断
if(cond1){
xxx
} else if(cond2){
# 必须同行!!!
xxx
} else{
# 必须同行!!!
xxx
}
# 行if
ifelse(cond,A,B)
#等价于 cond?A:B
循环
for循环
和python很相似,然后用花括号包起来,感觉没有c系有含金量
for(x in c(xx)){
xxx
}
while循环
while(cond){
xxx
}
函数
R的函数感觉怪怪的,给一个变量赋值,把函数当成一个变量了,解释型语言都喜欢这么干吧
值得注意的是return必须带上括号,变量作用范围就不用说了,和其他语言都差不多
x<-function(){
xxx
return(xxx)
}
画图
感觉是重头戏
par
设置之后图形的参数,有些参数只能由par来改
参数列表
| 属性名 | 作用 |
|---|---|
| bg | 背景色 |
| bty | 变量样式(o,l,7,c,u) |
| cex | 缩放倍数,子目标有, axis , lab , main , sub |
| col | 颜色,子目标有, axis , lab , main , sub |
| font | 字体样式,1正常,2粗体,3斜体,4粗斜体 |
| family | 字体种类 |
| las | 坐标轴数表样式 |
| pch | 点的形状,0正方形,1圆形,2三角形,3加号,4叉,5菱形 |
| lty | 线条type,0不画线,1实线,2虚线,3点线 |
| lwd | 线条witdh |
| str | 旋转角度,45就是45度,逆时针 |
| mfrow | 多图 c(a,b),a * b |
plot
设置坐标轴,参数是一堆坐标轴信息
参数列表
| 参数名 | 作用 |
|---|---|
| type | p点图,l折线图 |
| main | 主标题 |
| sub | 副标题 |
| xlab | x轴标题 |
| ylab | y轴标题 |
| asp | y/x的比 |
| xlim,ylim | x轴和y轴的界限,c(min,max) |
| col | 颜色 |
| cex | 倍率 |
| bg | 背景色 |
| frame.plot | 是否给图像加框 |
points(x,y,…)
加点
abline(a,b,h,v,reg,…)
- a,截距
- b,斜率
- h,水平线纵坐标
- v,垂线横坐标
- reg,不知道
segments(x0,y0,x1,y1)
线段
rect(xleft,ybottom,xright,ytop,…)
左下角,右上角 定位矩形
感觉不会考,不管了
text(x,y,”xxx”,…)
文本
mtext(“xxx”,side=3,…)
绘画框外绘制文本,side就选3吧
legend(x,y,legend,…)
图例
pie(x,…)
x是各个指标的百分比,然后指标的名字要自己names(x)<-c(A,B,C,…)
例题之类的
5.设置par,绘制一页多张图。
1)第一张图,不添加坐标轴
2)添加自定义坐标轴,横坐标为字母。
3)添加边框
4)添加第二张图,不添加坐标轴
5)添加自定义坐标轴,横坐标为字母,颜色为红色
op=par()
par(mfrow=c(1,2))
plot(1:10,type="l",xlab="", ylab="",axes=F)
axis(side=1,at=1:10,labels=LETTERS[1:10])
box()
plot(1:10,type="l",xlab="", ylab="",axes=F)
axis(side=1,at=1:10,labels=LETTERS[1:10],col.axis = "red")
3.绘制底图。要求
1)添加一个矩形
2)填充线密度设置为8根
3)填充线倾斜度设置为15度
4)灰色填充
5)矩形边框设置为红色
6)将矩形边框加粗
7)给整个图加一个粗度为3的外边框
plot(5,type="n")
rect(1,1, 3,3)
rect(3,3, 6,6,density = 8)
rect(3,3, 6,6,density = 8,angle = 15)
rect(1,7, 4,9,col="grey")
rect(1,7, 4,9, col="grey", border="red")
rect(1,7, 4,9, col="grey", border="red", lwd=3)
box(lwd=3)
- 随机产生10个数,对这个10数构成的向量进行绘画。要求:
1)添加标签。x轴为“随机数横轴”,y轴为“随机数纵轴”,标题为“可视化练习”
2)设置图标颜色为红色。
3)更改图标类型为圆形
4)更改图标大小为3倍大小
5)更改类型为划线
6)更改线条宽度为3倍
7)更改线条类型为虚线
8)限制y轴大小为0.3到0.8之间
9)不画边框
data=runif(10)
plot(data,xlab="随机数横轴",ylab="随机数纵轴",main="可视化练习")
plot(data,col="red")
plot(data,col="red",pch=16)
plot(data,col="red",pch=16,cex=3)
plot(data,type="l")
plot(data,type="l",lty=4)
plot(data,type="l",lty=4,ylim=c(0.3,0.8),frame.plot="F")
dplr
需要library(tidyverse)
这个模块类似sql啊
filter筛选
筛选出一个子集,第一个参数是数据框,之后是表达式
filter(data,cond1,cond2)
# 条件1和条件2是与关系
filter(data,cond1|cond2)
# 这是或关系,不想管先后运算顺序就用括号吧
arrange重排
不选择行,而是改变行的顺序,按照关键字排序,默认是升序,用desc可以降序
select选择
这些dplr里的函数用法都差不多
第一个参数是数据集,之后的参数是要选择出来的列关键字,可以用冒号选连续,也可用减号去掉列
# 选择year到day中间的所有列
select(flights,year:day)
# 不选择year到day中间的列
select(flights,-(year:day))
stringr包
很多方法不是R语言自带的吗,为什么要再来一遍,只讲讲正则表达式吧
str_view(vector,regex)
这个和grep是反一下的,输入的向量参数是在前面的,grep是反过来的
然后这个结果是打开一个网页显示筛选结果,而不是在命令行里输出
x<-c("apple","banana","pear")
str_view(x,"an")
现在是考后复盘时间
完全没有考画图的知识点
全是一些基础数据结构的题目
向量负下标的作用
数据框增加列
最难的应该是字符频次统计,不会
应该是当时有关红楼梦的实验题,当时因为觉得正则表达式是重点,所以没仔细看
不考画图大概是画图都是纯记忆
后面还要写论文,那时候就要用到画图了
还要写论文,真麻烦啊
2022/11/22