
SHA-1 的计算方法
SHA-1 (Secure Hash Algorithm 1) 是一种杂凑算法(哈希算法),计算结果会用40个十六进制数字呈现,该算法的特点是输入相同的输入就会有一样的输出结果
因为是哈希的输出固定为40的十六进制数字,所以理论上不同的两个输入其实是有完全相同输出的可能的,这种情况就被称为是碰撞(Collision),但是碰撞的概率非常低,再加上 git 再额外加了点 salt,所以碰撞的概率会更低,所以一般相同的 SHA-1 就是说明输入是相同的
计算公式
在 git 中,不同种类对象的 SHA-1 的计算方法会略微不同,例如,Blob 对象的 SHA-1 组成模式如下:
- “blob”
- 空白
- 输入内容的长度
- Null 结束符号
- 输入内容
而如果是 Tree 对象,第一项则为 “tree”,如果是 Commit 对象,则会改成 “commit”,以此类推
我们从上面的组成模式中可以看出,Blob 的这几项都没有和时间有关的内容(COmmit 对象和 Tag 对象的内容包括时间),所以以 Blob 对象来说,不管在什么时间或设备上(注意,Blob是不包含文件名的),一样的文本内容都会有一样的文本输出,作为验证可以在自己的终端下尝试
$ echo "hello, 5xRuby"|git hash-object --stdin
30ab28d3acb37f96ad61ad8be82c8da46d0a7307
看看你得到的输出是否和我相同,上面用到的是 git 内置的 hash-object 命令计算,当然你也可以用其他语言的 SHA-1 库对比计算结果是不是一样,但是这时候输入不算直接输入字符串,而是需要改成上面的格式(blob 长度\0输入内容)
书上没有讲到 SHA-1 的具体算法,不过这些哈希加密的算法其实为了不碰撞都很复杂玄学,但是我们只需要知道 git 的 SHA-1 就是这样算出来的就好了
下面一小节不想看可以直接跳过或者看小结,但是跟着看一遍可以加深对 git 的理解
探索 .git 目录
想要我的财宝吗?想要的话可以全部给你,去找吧!我把所有的财宝都放在那里了。
--《航海王》哥尔罗杰
对于 git 来说,.git 目录扮演的就是宝藏这样的角色,所有的记录、备份都放在其中了,所以想要真正地学号 git,建议花一些时间来摸清这个目录中到底藏了什么东西,这样就更能理解 git 的运行原理,操作起来更加得心应手
在开始之前,我们要先知道在 git 中有4种很重要的对象,分别是 Blob、Tree、Commit、Tag 对象
接下来让我们通过实际操作 git 命令,详细介绍这些对象的关联性
创建文件
$ echo "hello, 5xRuby" > 1.tmp
# 只有 git add 之后文件才会被 git 管控
$ git add 1.tmp
上面我们已经测试过这句话用 git 的 SHA-1 计算公式算出来的值是 30ab28d3acb37f96ad61ad8be82c8da46d0a7307 ,我们这时候来看 .git/objects
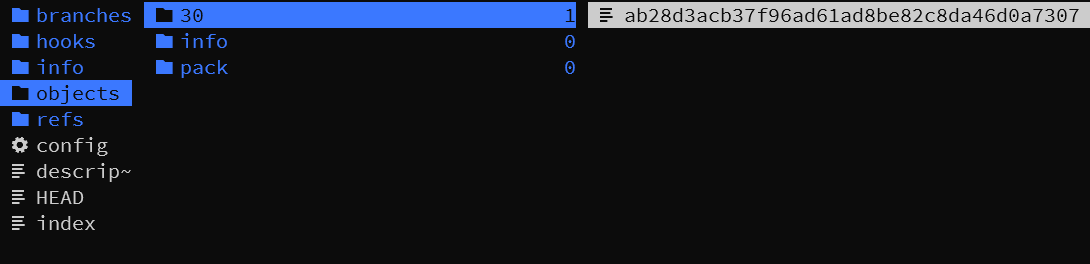
发现这个文件夹的名字的两个字母,加上后面那个文件的38字母的文件名正是我们之前算出来的 SHA-1 值,因为文件的内容已经经过了压缩,所以用一般的文本编辑器是看不出内容的,但是我们可以用 git cat-file 命令来查看
$ git cat-file -t 30ab28d3acb37f96ad61ad8be82c8da46d0a7307
blob
-t 参数表示要查看的 SHA-1 值所代表的对象的形态,根据结果,git 说这个 SHA-1 值对应了一个 blob 对象,如果用 -p 参数
$ git cat-file -p 30ab28d3acb37f96ad61ad8be82c8da46d0a7307
hello, 5xRuby
就可以看到那个对象的内容了,由此过程我们可以得到以下信息
- 当使用 git add 命令把文件加入暂存区时,git 会根据这个对象的内容计算出 SHA-1 值
- git 接着会用 SHA-1 的值的前2个字节作为目录名称,后38个字节作为文件名,创建文件并存放在
.git/objects目录下 - 文件的内容则是 git 使用压缩算法把原本的内容压缩之后的结果(压缩算法 和 SHA-1 是两码事)
💡 在某些操作系统下,一个目录中如果放了非常多的文件,该目录的读取效率就会变得非常低,所以 git 就抽出了前两位数作为目录名,这是为了避免
.git/objects目录因为文件过多而导致效率变低
创建文件夹
$ mkdir dir
$ git status
On branch master
No commits yet
Changes to be committed:
(use "git rm --cached <file>..." to unstage)
new file: 1.tmp
为啥没反应呢?那是因为 git 只会对文件的内容进行 SHA-1 计算,因为 dir/ 是一个空的文件夹,根本没有内容,所以 git 感应不到
⚠ git 不会管控的文件夹
空文件夹里创建文件
$ touch dir/new
$ git status
On branch master
No commits yet
Changes to be committed:
(use "git rm --cached <file>..." to unstage)
new file: 1.tmp
Untracked files:
(use "git add <file>..." to include in what will be committed)
dir/
新建了文件之后,这个文件夹就能被 git 看到了
💡 就算是一个空的文件,也是有文件内容的
我们把它添加到暂存区
$ git add dir/new
根据文件的内容我们来计算以下 dir/new 的 SHA-1,
$ cat dir/new | git hash-object --stdin
e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
按照之前的结论,应该会在 .git/objects 文件夹里建立 e6/9de29bb2d1d6434b8b29ae775ad8c2e48c5391
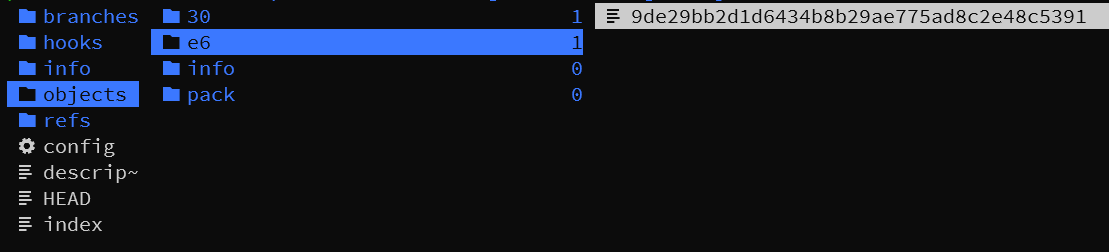
果然如此,到这里大概对 git 的 blob 对象有一个大致的认识了吧
你可能会好奇,为什么 git 只在意文件的内容,难道目录就不重要吗,文件的名称就不重要吗?
其实只是因为他们不属于 blob 对象的范围,而是之后要说的 Tree 对象要处理的
进行提交
文件已经加入暂存区了,接下来我们来看看 commit 操作会对 .git/objects 产生什么影响
$ git commit -m "init commit"
[master (root-commit) 275c688] init commit
2 files changed, 1 insertion(+)
create mode 100644 1.tmp
create mode 100644 dir/new
查看 .git/objects 文件夹
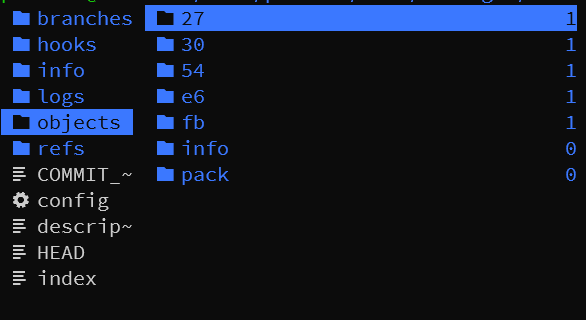
发现除了原本的 30 和 e6 文件夹之外,又多出了好几个目录,我们来看看它们分别都是什么
先来看 27
$ git cat-file -t 275c688fee8cab4a417dbb4efd03e7fc5e8298a3
commit
git 告诉我们这是一个 commit 对象
来看看它的内容是什么
$ git cat-file -p 275c688fee8cab4a417dbb4efd03e7fc5e8298a3
tree 54963fdf9b71ab2e8712cc84e1c61dbf8c3bfad6
author lol <233@qq.com> 1673122354 +0800
committer lol <233@qq.com> 1673122354 +0800
init commit
这个 commit 对象包括以下信息
- 某个 tree 对象
- 作者和修改完成的时间
- 提交者和提交的时间,通常作者和提交者是同一个人,但也会有其他情况
- 本次提交的信息
我们来看看这个 commit 对象里放的 tree 对象是什么吧
$ git cat-file -t 54963fdf9b71ab2e8712cc84e1c61dbf8c3bfad6
tree
不出意料它是一个 tree 对象,来看看内容
$ git cat-file -p 54963fdf9b71ab2e8712cc84e1c61dbf8c3bfad6
100644 blob 30ab28d3acb37f96ad61ad8be82c8da46d0a7307 1.tmp
040000 tree fb94905aafbdcb5da3091bba933cdb2e391e88a7 dir
我们看到它包含了一个 tree 对象和一个 blob 对象,而这个 blob 对象正是我们第一个新建的文件 1.tmp ,而另一个 tree 对象则有说明是 dir,这样看的话,这个 tree 对象应该就是根目录,我们最后来看以下 fb9490 的内容,如果是 dir 文件夹的话,应该有 new 空文件的信息
$ git cat-file -p fb94905aafbdcb5da3091bba933cdb2e391e88a7
100644 blob e69de29bb2d1d6434b8b29ae775ad8c2e48c5391 new
果然它指向了我们刚刚创建的空文件 new,看到这里大概也对 tree 对象有一个了解了吧
结果上面的结果,我们可以得出以下结论:
文件在 git 中会以 blob 对象的形式存放,如
1.tmp和newblob 中会存放压缩过的文件内容
目录和文件则是会以 tree 对象的形式存放,如
54963f是根目录,fb9490是dir目录tree 中会指向另一个 tree 对象或者 blob 对象,并含有他们的名称信息
commit 对象会指向某个 tree 对象,包含 commit 的各种信息
用程序呈现出来可能有点模糊,用图片的形式整理出来就是这样的
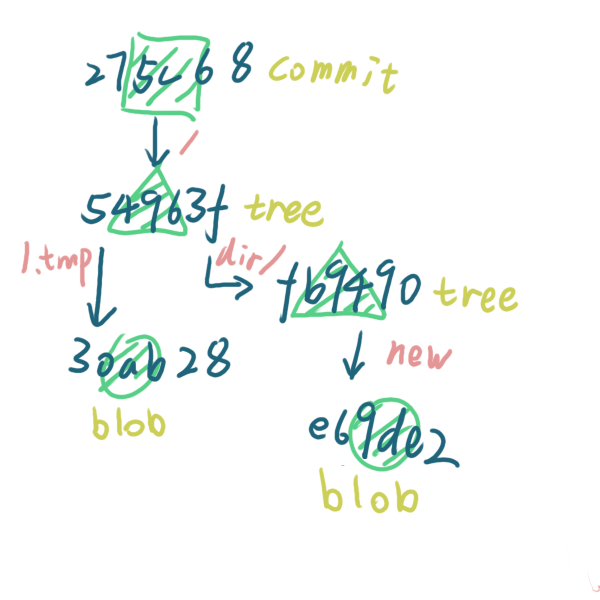
你看到这幅图可能觉得他们的关系和目录和子目录之间的关系相同,但其实并不相同,它有一个专有名词 —— 有向无环图(DAG, Directed Acyclic Graph),这些对象只有指来指去,是平行的,并没有像目录和子目录之间的层级关系,而上面的文件或者文件夹名并不是指 指向的文件或者文件夹就是这个对象,而是 这个对象的内容来自于这个文件或文件夹,听起来可能很绕,你可以觉得他们并不是图,而是一颗树,我们来看下面的例子
$ mkdir try
$ cd try
$ git init .
Initialized empty Git repository in /home/paradox/Code/learngit/try/.git/
$ touch tmp1
$ touch tmp2
$ git add .
$ git commit -m "first commit"
[master (root-commit) f8993a0] first commit
2 files changed, 0 insertions(+), 0 deletions(-)
create mode 100644 tmp1
create mode 100644 tmp2
$ cd .git/objects/
$ ls
87 e6 f8 info pack
$ git cat-file -p f8993a02952879d158d2c520c8e96cf5324d1d4c
tree 87cc6b1d469b5fa6bd1eaa5147caaa04867eb2dc
author lol <233@qq.com> 1673126388 +0800
committer lol <233@qq.com> 1673126388 +0800
first commit
$ git cat-file -p 87cc6b1d469b5fa6bd1eaa5147caaa04867eb2dc
100644 blob e69de29bb2d1d6434b8b29ae775ad8c2e48c5391 tmp1
100644 blob e69de29bb2d1d6434b8b29ae775ad8c2e48c5391 tmp2
解释一下,我们创建了两个空文件 tmp1 和 tmp2,然后查看 commit 指向的 tree 对象,里面有两个一模一样的 SHA-1,后面还有我们创建的空文件名,这是因为这两个文件都是相同的内容,根据 SHA-1 算法,相同内容计算出的结果是一样的,因此他们都指向了 e69de2 ,你应该明白他们并不是层级关系,也不是树形关系,而是 DAG的关系,和 e69de2 代表的是空内容,而不是那个文件了吧!
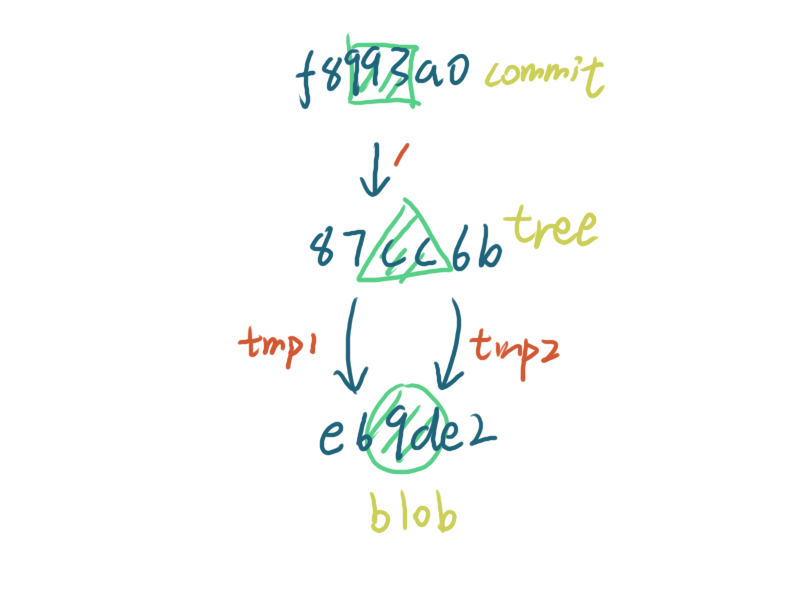
到目前为止,git 的四大对象中的出现了三种已经出现了,还剩一个 tag 对象
加上分支
git 中的分支其实就是跟贴纸一样,它会贴在某个 commit 上,并且会随着 commit 移动。之前也对 HEAD 的介绍中指出,HEAD 是指向某个分支的指针,那个分支一般就指当前所在的分支,所以在上面的图上加上这条信息就是
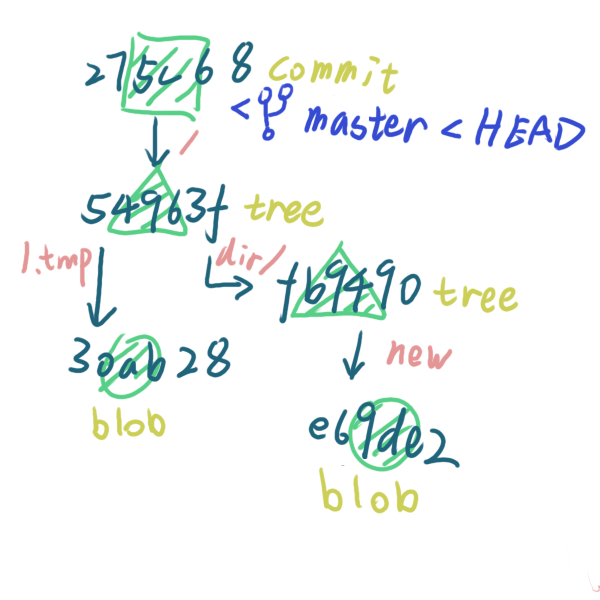
提交一次修改
这次我们来修改一下 1.tmp
$ cat 1.tmp
hello, world
- hello, 5xRuby -
hello, git
我们先来计算一下这个文件对应的 SHA-1
$ cat 1.tmp | git hash-object --stdin
1f169b152ea986dfa8f171ece502788674ac5334
添加到暂存区
$ git add 1.tmp
这时候先别急着提交,我们来看看 .git/objects 有没有新发现

不出意外的添加了这个文件内容对应的 SHA-1 ,现在的 .git/objects 文件夹的状态是下面这样
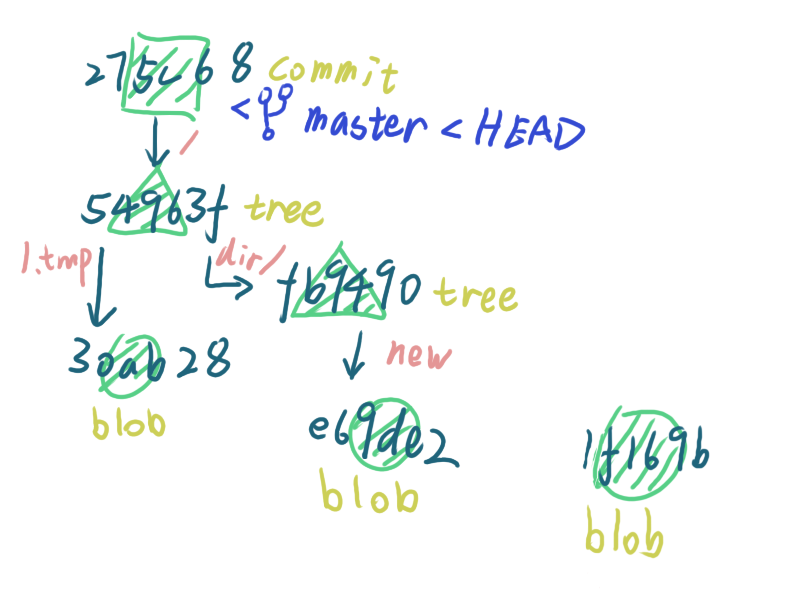
接下来我们提交这次修改
$ git commit -m "3rd commit"
[master 7ee420d] 3rd commit
1 file changed, 3 insertions(+), 1 deletion(-)
现在再来看看 .git/objects

和之前的进行对比会发现多了 7e 和 71 这两个文件夹,我们一个个来看
$ git cat-file -t 712598bd0ec8b76460f154bc2c4090184ef628ee
tree
$ git cat-file -p 712598bd0ec8b76460f154bc2c4090184ef628ee
100644 blob 1f169b152ea986dfa8f171ece502788674ac5334 1.tmp
040000 tree fb94905aafbdcb5da3091bba933cdb2e391e88a7 dir
这个 tree 对象看上去和上一个 commit 中代表根目录的 tree 很相似,只是内容有点不太一样,对比一下会发现指向 dir 的文件夹那行没有改变,只有 1.tmp 那行发生了变化,因为文件内容改变了,所以指向了新的 blob 对象
我们再来看另一个
$ git cat-file -t 7ee420da8e453e54832bb7914f03e23f6f4f8302
commit
$ git cat-file -p 7ee420da8e453e54832bb7914f03e23f6f4f8302
tree 712598bd0ec8b76460f154bc2c4090184ef628ee
parent 275c688fee8cab4a417dbb4efd03e7fc5e8298a3
author lol <233@qq.com> 1673129549 +0800
committer lol <233@qq.com> 1673129549 +0800
3rd commit
7ee420 是一个 commit 对象,从给出的信息中可以看出它指向了刚刚的 tree 对象 712598 ,除此之外还多出了一个 parent 信息,表示指向上一次 commit,当前的状态可以表示成如下图
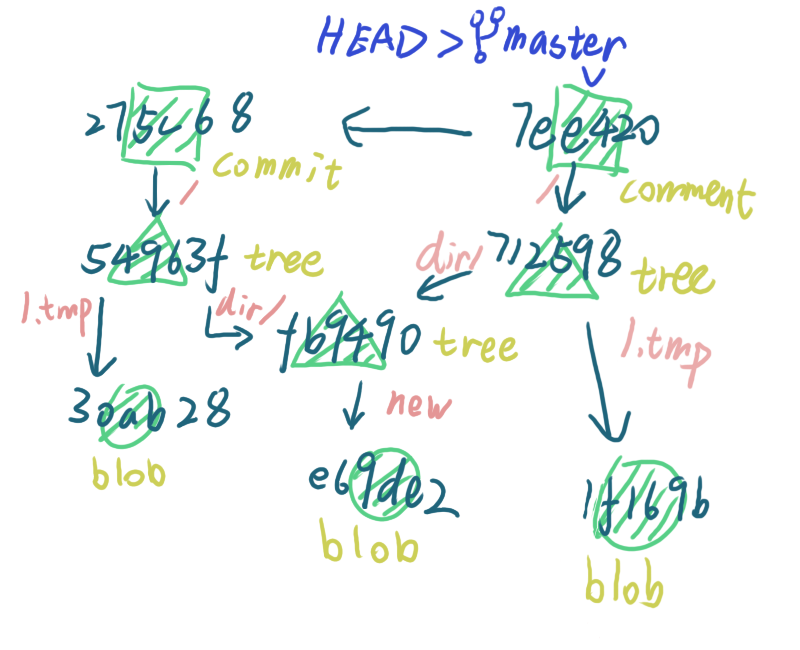
分支和 HEAD 也是随着 commit 的变化而调整位置,把前后两次提交之后的图放一起对比会形象不少
在上面得出的结论基础上,我们还可以再加一条
- 除了第一个 commit 对象,所有的 commit 对象都会指向其前一次 commit 对象
tag 对象
tag 对象不会再 commit 的时候出现,必须手动把 tag 贴在某个 commit 上,关于 tag 的具体介绍会放在后面,现在我们只需要知道这个对象在 .git 文件夹里的状态就可以了
我们来打上一个 tag
$ git tag -a aTag -m "I am a Tag in here"
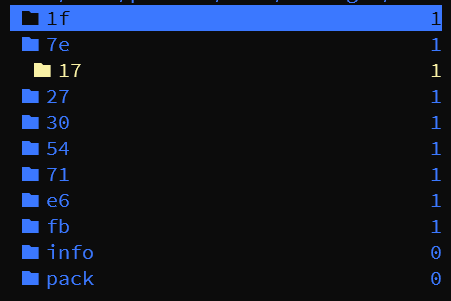
此时 .git/objects 中多出了 17 文件夹,我们来查看一下 tag 对象的内容会是什么样的
$ git cat-file -t 17862cfb31505c0114ea4e40fa4ae481558559e3
tag
$ git cat-file -p 17862cfb31505c0114ea4e40fa4ae481558559e3
object 7ee420da8e453e54832bb7914f03e23f6f4f8302
type commit
tag aTag
tagger lol <233@qq.com> 1673133569 +0800
I am a Tag in here
它会指向标记的提交,还有记录是谁在什么时候做了这个 tag 以及这个 tag 的相关信息
所以最终的状态如下
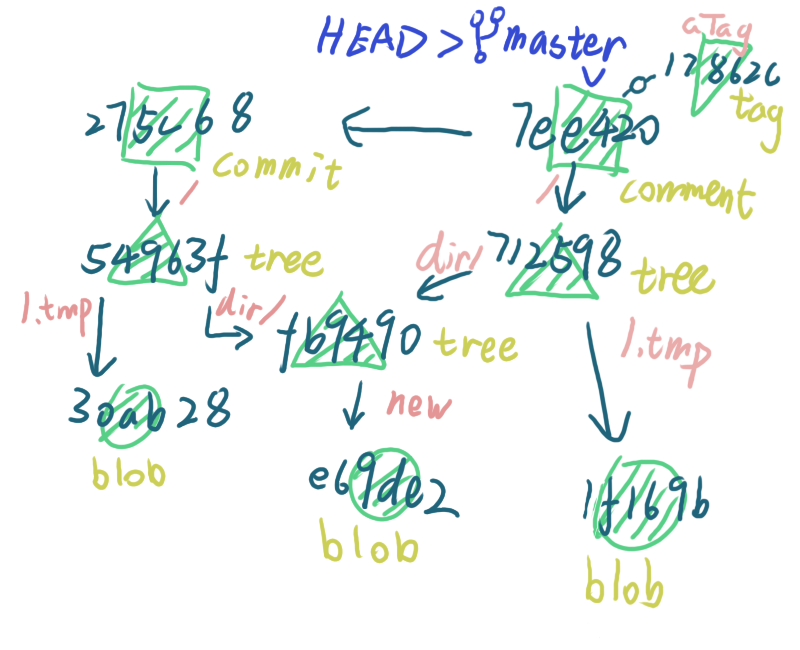
checkout
虽然 .git/objects 目录中保留了所有的文件和文件夹,但是在工作目录中还是会根据当前的 commit 把各种对象给提取出来,所以工作目录的状态如下图不透明部分所示
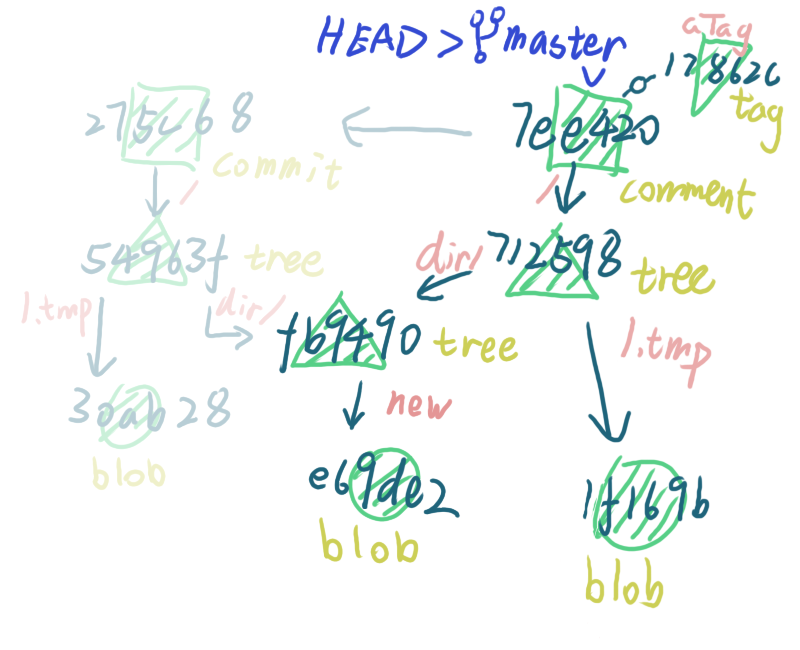
当我们 checkout 到另一个 commit 时,就会出现下面的说明
$ git log --oneline
7ee420d (HEAD -> master, tag: aTag) 3rd commit
275c688 init commit
$ git checkout 275c688
Note: switching to '275c688'.
You are in 'detached HEAD' state. You can look around, make experimental
changes and commit them, and you can discard any commits you make in this
state without impacting any branches by switching back to a branch.
If you want to create a new branch to retain commits you create, you may
do so (now or later) by using -c with the switch command. Example:
git switch -c <new-branch-name>
Or undo this operation with:
git switch -
Turn off this advice by setting config variable advice.detachedHead to false
HEAD is now at 275c688 init commit
因为 275c688 这个 commit 没有分支指着,而我们的 HEAD 如果前往,就会发生之前提到的 detached HEAD,关于 detached HEAD 会之后再具体介绍,当我们切换到这个节点的时候,git 会根据当前这条 commit 的信息计算出哪些文件需要被提取到工作目录中,所以现在的 1.tmp 的文本内容是这样的
$ cat 1.tmp
hello, 5xRuby
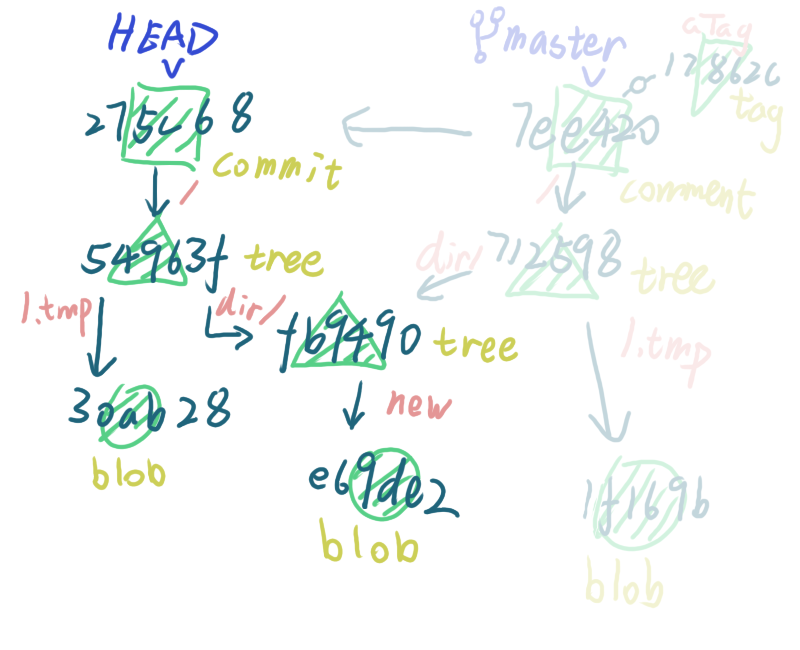
checkout 的过程有点像拎葡萄,还是很好理解的(?哪有颗葡萄连着两个枝的
疑问
看到这里你应该也会和我一样惊讶于 git 的原理,之前我以为 git 是采取只会保留每次修改了哪些内容的差异备份机制,结果看完发现 git 并不是这么设计的
从前面的流程看,我们每次 git add 一个文件,哪怕只修改了一个字,由于计算出来的 SHA-1 的值不同,git 都会为它新建一个 blob 对象,而不是去记录文件的前后变化差异
这样做有一个好处,那就是 checkout 的时候不用一步步去拼凑历史记录,checkout 的效率非常高,有些人把这个过程称为 Snapshot(快照)
但是这样做的代价不就是需要大量的空间来存放文件,试想一下,如果有一个 100KB 的文件,因为改了一行代码就必须再做出一个 100KB 的文件放在 .git/objects 里,虽然 git 会对文件内容进行压缩,但是只是因为一行代码就备份整个文件这个行为未免太浪费了
而对此,git 也是给出了它的方案,git 提供『资源回收机制』,当启动这种机制的时候,git 就会非常高效地压缩对象和制作下标,下面我们来演示一下这个机制
$ git ls-files -s
100644 1f169b152ea986dfa8f171ece502788674ac5334 0 1.tmp
100644 e69de29bb2d1d6434b8b29ae775ad8c2e48c5391 0 dir/new
$ git cat-file -s 1f169b152ea986dfa8f171ece502788674ac5334
42
git ls-files 能够查询当前文件在 git 中的样子,git cat-file 后面加上 -s 参数则会输出指定文件的 blob 对象的文件大小,1.tmp 的 blob 对象有 42 bytes 那么大
接下来我们来增加一行做一次提交
$ cat 1.tmp
hello, world
- hello, 5xRuby -
hello, git
does git need to stage all
$ git add .
$ git commit -m "modify 1.tmp"
[master 39886fe] modify 1.tmp
1 file changed, 1 insertion(+)
我们增加了一行 does git need to stage all ,按照 git 的机制,肯定会新建一个 blob 对象,我们来看看这个 blob 对象有多大
$ git ls-files -s
100644 82b26dc0fa6931b634fcf196ca8076213f46ed12 0 1.tmp
100644 e69de29bb2d1d6434b8b29ae775ad8c2e48c5391 0 dir/new
$ git cat-file -s 82b26dc0fa6931b634fcf196ca8076213f46ed12
69
有 69bytes !!只为了一行字,git创建了一个 69bytes 的 blob 对象,这就是前面说的浪费
但此时 git 并没有启用『资源回收机制』,我们来看看启用之后的效果,git 的『资源回收机制』通常会在它认为对象太多时候启用,但也可以用 git gc 手动触发
$ git gc
Enumerating objects: 12, done.
Counting objects: 100% (12/12), done.
Compressing objects: 100% (8/8), done.
Writing objects: 100% (12/12), done.
Total 12 (delta 0), reused 0 (delta 0), pack-reused 0
这条命令会把原本在 .git/objects 目录下的对象全部打包到 .git/objects/pack 目录下成 .idx 和 .pack 文件
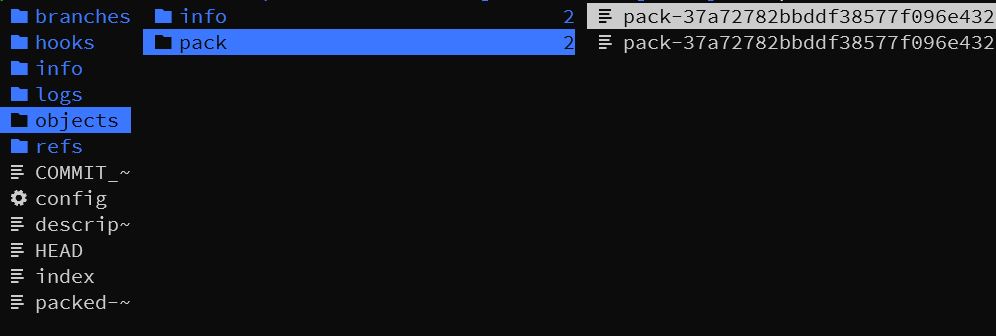
git 还有一个底层的命令 git verify-pack 可以用于查看打包的情况
$ git verify-pack -v pack-37a72782bbddf38577f096e432a1622bff6d27ea.idx
39886fe807a8eaf236ca3a1edf5d13228b4c8639 commit 193 142 12
7ee420da8e453e54832bb7914f03e23f6f4f8302 commit 191 138 154
17862cfb31505c0114ea4e40fa4ae481558559e3 tag 130 124 292
275c688fee8cab4a417dbb4efd03e7fc5e8298a3 commit 144 111 416
c1078872df94c18b353dc779fb60a55d7534b7c5 tree 63 74 527
fb94905aafbdcb5da3091bba933cdb2e391e88a7 tree 31 42 601
712598bd0ec8b76460f154bc2c4090184ef628ee tree 63 74 643
54963fdf9b71ab2e8712cc84e1c61dbf8c3bfad6 tree 63 74 717
82b26dc0fa6931b634fcf196ca8076213f46ed12 blob 69 67 791
e69de29bb2d1d6434b8b29ae775ad8c2e48c5391 blob 0 9 858
1f169b152ea986dfa8f171ece502788674ac5334 blob 42 42 867
30ab28d3acb37f96ad61ad8be82c8da46d0a7307 blob 14 23 909
non delta: 12 objects
pack-37a72782bbddf38577f096e432a1622bff6d27ea.pack: ok
上面的信息第1栏是对象的 SHA-1 值,第2栏是对象的形态,第3栏是文件的大小,我这里看下来好像文件的大小并没有改变…
可能是因为文件都还太小,git 懒得压缩,但是书上的例子确实会让 blob 对象文件变小,说是 git 在资源回收打包的时候使用了类似差异备份的方式,有效的缩小了对象的体积
git 启用『资源回收机制』的时机
- 当
.git/objects目录的对象或者打包过的 packfile 数量过多时会自动触发 - 当执行
git push命令推送到远端服务器的时候
💡 其实 git 并不在意空间的浪费,能够快速操作才是 git 关注的重点
小结
git 中的4中对象的关系如下图所示
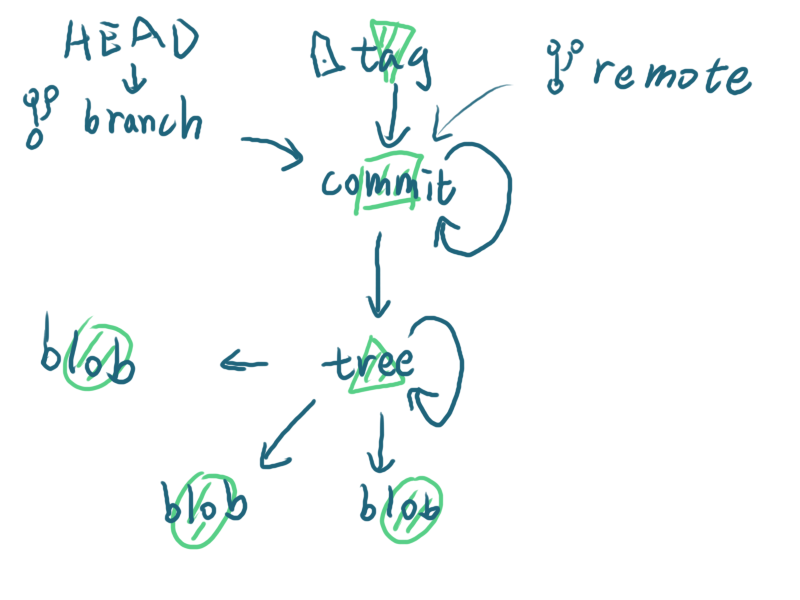
- 把文件加入 git 后,文件的内容会以 blob 对象的形式存储
- 目录及文件名会存放在 tree 对象内,tree 对象会指向 blob 对象或者其他的 tree 对象
- commit 对象会指向某个 tree 对象。除了第一个 commit,其他的 commit 会指向前一次 commit 对象
- tag 对象会指向某个 commit 对象
- 分支虽然不属于对象,但是它会指向某个 commit 对象
- 往 git 服务器 push 之后,在
.git/refs下就会多出一个remote目录,里面放的是远端的分支,和本地的分支类似,会指向某个 commit 对象 - HEAD 也不属于对象,会指向某个分支
- git 的 checkout 很快是因为 git 没有采用差异备份方式,而是用空间换时间
2023/01/08这一篇真的花了我好长时间,
其实是容易摸鱼不过真的学到了好多东西,git 居然不是用差异备份,这真的震撼到我了😦